크롤링을 왜 하지? 라는 생각을 해본다.
1) 원하는 정보의 뉴스만 가져오고 싶어서
2) 그 행위를 자동화 하고 싶어서
아마 저 2가지 이유일거라 생각이 된다.
그래서 오늘은 일단 간단하게 종목들에 대해 주요 기사를 가져오는 방법을 공유해본다.
※ 크롤링에 대한 방법은 아래 블로거 및 유튜브 내용을 참고했습니다.
1) https://juran-devblog.tistory.com/88
2) https://wonhwa.tistory.com/46
3) https://www.youtube.com/watch?v=U1amkBqKF5g&t=2s
1. Open API 설정.
- 종목명을 가져오는 것은 우선 본인의 경우 kiwoom Open API를 활용하고 있다.
- 방식은 여러방법이 있겠지만, Open API를 쓰는 이유는 결국 실시간 조회 및 자동매매 활용을 위한 목적이 있기 때문.
- Open API를 활용한 종목 가져오는 방법도 이미 공유 된 소스가 많다.
- 그 중 간단하게 wikidocs에 올라 와 있는 방법을 공유한다.
1) https://wikidocs.net/6235
2) https://wikidocs.net/77483
우선은 간단한 방식은 위 저자(조대표님)가 만들어둔 모듈 pykiwoom을 사용하는 2)이다.
그러나, 직접 쓰고 싶은 함수를 Open API를 보면서 가지고 와서 실행해보고 하는 것이 도움이 된다 생각하고,
여유가 된다면 1)방식을 참조해서 해보길 권해봅니다.
1) 방식을 활용한 kiwoom Open API 접속하기.
import sys
from PyQt5.QtWidgets import *
from PyQt5.QAxContainer import *
from PyQt5.QtCore import *
class Kiwoom:
def __init__(self):
self.ocx = QAxWidget("KHOPENAPI.KHOpenAPICtrl.1")
self.ocx.OnEventConnect.connect(self._handler_login)
def CommConnect(self):
self.ocx.dynamicCall("CommConnect()")
self.login_loop = QEventLoop()
self.login_loop.exec()
def GetLoginInfo(self, tag):
data = self.ocx.dynamicCall("GetLoginInfo(QString)", tag)
return data
def GetCodeListByMarket(self, market):
data = self.ocx.dynamicCall("GetCodeListByMarket(QString)", market)
codes = data.split(";")
return codes[:-1]
def GetMasterCodeName(self, code):
data = self.ocx.dynamicCall("GetMasterCodeName(QString)", code)
return data
def _handler_login(self, err):
self.login_loop.exit()
app = QApplication(sys.argv)2. 종목가져오기 및 뉴스크롤링 함수 정의.
class PyAuto:
def __init__(self):
# Kiwoom 클래스의 객체를 생성
self.kiwoom_blog = Kiwoom()
self.kiwoom_blog.CommConnect() # 로그인한다.
# self.kiwoom.GetConditionLoad() # 조건식 가져온다.
def GetCodeListByMarket(self):
self.kospi_codes = self.kiwoom_blog.GetCodeListByMarket(MARKET_KOSPI)
self.kosdaq_codes = self.kiwoom_blog.GetCodeListByMarket(MARKET_KOSDAQ)앞서 작성된 kiwoom_blog 파일로부터 Kiwoom 클래스를 호출하고,
GeetCodeListByMarket이란 함수를 통해서 코스피, 코스닥 종목들을 가져옵니다.
그리고, 크롤링을 위한 함수를 정의하는데,
이때 크롤링 할 대상을 '종목코드'로 세팅합니다.
그래서, 종목별로 뉴스기사를 크롤링 할 수 있게 되는것입니다.
def crawling(self,code):
now = time.strftime('%H%M%S')
today = datetime.today().strftime("%Y-%m-%d")
print("현재시간 : %s" % now)
keyword = self.kiwoom_blog.GetMasterCodeName(code)
# 관련도순 : Ar, 최신순 : Add
alignment = {'관련도순' : '0','최신순' : '1'}
align = alignment['최신순']관련도순보다는 최신순으로 하였고, 추후 최신순에서 제목에 해당 종목이름이 들어간 것만 추출합니다.
align을 최신순으로 하여 뉴스 화면의 정렬방식을 정의 해 줍니다.
목적에 따라 정렬방식을 정하면 되겠으나,
이미 지나간 뉴스가 아닌 실시간으로 방금 뜬 기사를 보고 싶다면 최신순으로 정렬하고 1페이지만 보면 충분합니다.
# 뉴스기사 가져오기. // 최신것만 가져올 것이므로 최신순 정렬 후 1페이지만 본다.
response = requests.get("https://search.naver.com/search.naver?where=news&query=" + keyword + "&sm=tab_opt&sort=" + align + "&photo=0&field=0&pd=0&ds=&de=&docid=&related=0&mynews=0&office_type=0&office_section_code=0&news_office_checked=&nso=so%3Ar%2Cp%3Aall&is_sug_officeid=0")
html = response.text
soup_title = BeautifulSoup(html,'html.parser')
links = soup_title.select(".news_tit")
위의 방식대로 기사를 정렬했으면,
제목과 url을 가져옵니다.
추후 df화 하기 위해 title과 url은 각각 list 형식으로 넣어줍니다.
# 기사의 제목하고 Url만 가져오기
news_title = []
news_url = []
for link in links:
title = link.text #기사 타이틀 태그 안에 text(제목만)를 가져온다.
url = link.attrs['href'] #href의 속성값을 가져온다.
if keyword in title: # 제목에 키워드가 있는것만 뽑아오겠다.
news_title.append(title)
news_url.append(url)기사 제목과 url을 다 뽑고 나면 df에 넣어줍니다.
그리고, 관련도 없는 기사들 즉, 제목에 이름도 들어가지 않은 기사들은 필요 없겠죠.
그래서 이미 위의 코드에서 제목에 키워드(종목명)가 있는 것만 넣기로 했고,
한번더 확인을 위해서 핵심기사가 없으면 없다고 출력 해줍니다.
len(df_news) < 1 이란 뜻은,
제목에 종목명이 들어간 기사가 하나도 없다는 뜻입니다.
df_news = pd.DataFrame({'종목명' : keyword, 'Title': news_title, 'URL': news_url, 'date' : today,'Searchtime' : int(now)})
if len(df_news) < 1:
print("%s 관련 핵심기사가 없습니다." % keyword)
# print(df_news)
# print(tabulate(df_news, headers='keys', tablefmt='plain', showindex=True, stralign='left'))
return df_news3. 구동.
이제 구동시켜봅니다.
위에서 받아온 코스피,코스닥 종목코드들을 종목코드와 종목명으로 딕셔너리에 넣어줍니다.
def run(self):
self.kospi_codes = self.kiwoom_blog.GetCodeListByMarket(MARKET_KOSPI) ## 리스트
self.kosdaq_codes = self.kiwoom_blog.GetCodeListByMarket(MARKET_KOSDAQ) ## 리스트
for code in self.kospi_codes:
kospi_dict.update({code : self.kiwoom_blog.GetMasterCodeName(code)})
for code in self.kosdaq_codes:
kosdaq_dict.update({code: self.kiwoom_blog.GetMasterCodeName(code)})
그리고, 종목별로 계속 for 문 돌리면서 뉴스기사를 크롤링 합니다.
# 종목별로 신규 기사 발굴하기
for code in kospi_dict.keys():
print("코스피 %s 뉴스기사 크롤링합니다" % kospi_dict[code])
print(self.crawling(code))
for code in kosdaq_dict.keys():
print("코스닥 %s 뉴스기사 크롤링합니다" % kosdaq_dict[code])
print(self.crawling(code))정상적으로 실행된 화면.
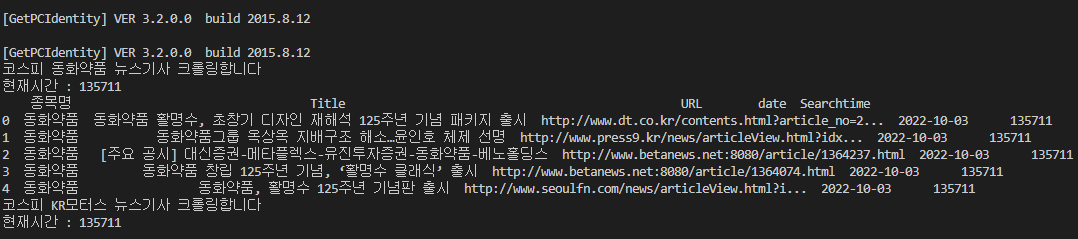
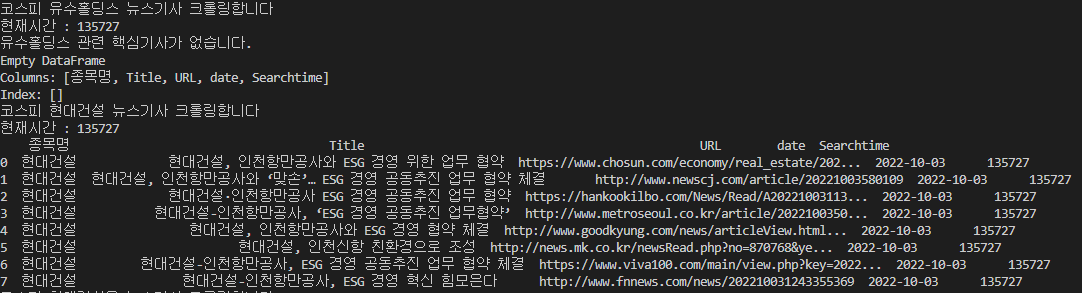
유첨파일로 코딩전체를 공유하니, 참고해서 활용해보시면 되겠습니다.
'주식공부 > 파이썬 주식' 카테고리의 다른 글
| vscode에서 pip 오류가 뜨는 경우. / 'pip' 용어가 cmdlet, 함수, 스크립트 파일 또는 실행할 수 있는 프로그램 이름으로 인식되지 않습니다. (0) | 2022.12.01 |
|---|---|
| 파이썬 주식, 지지선과 저항선 순번 매기기 - 1 (2) | 2022.10.03 |
| 데이터프레임에 Scalar 값만 들어가면 에러가 뜬다. - If using all scalar values, you must pass an index (0) | 2022.09.30 |
| 데이터프레임에 append가 안된다고.. (0) | 2022.09.30 |
| 파이썬 주식, 지지선/저항선을 그려보자 (2) | 2022.09.30 |